Is automatic Pinyin transcription feasible? I tested Google MT and Key5.
TL;DR: Machine-generated transcriptions are good enough to make Chinese text accessible, by and large, if you can’t fluently read Hanzi yet. Key5 and Google MT both bring their own idiosyncratic error profile to the table. I provide a qualitative comparison and a word-by-word evaluation on a sample text.
The Chinese script poses a well-known challenge for learners of Mandarin as a second language. A large number of symbols needs to be memorized, and the script encodes phonetic information in a way that makes it impossible, in practice, to read unknown characters.
Pinyin[1] is a romanization and orthography for writing Mandarin phonetically, with Latin letters. For details, Mark Swofford’s website[2] is a great resource. Pinyin has been in use in the PRC since the 1950s, but in practice its usage has remained limited to the first years of primary school, teaching Chinese as a second language, and the transliteration of proper names, e.g., on street signs. Consequently, no significant corpora exist in Pinyin, let alone parallel corpora with both characters and Pinyin.

This is where the automatic transcription of character text into proper Pinyin comes into play. If there is a way to reliably do that, then as a learner I can leave the somewhat artificial world of textbooks and graded readers and go straight to real-life content. This is what I do with every other foreign language that I learn: closely read a lot of interesting and fresh real-life text, without expending most of the effort on the script instead of the language.
The challenge
The automatic transcription of Chinese character text is difficult for two main reasons.
Word boundaries. Character text does not indicate them, but Pinyin does. Chinese word segmentation is a whole science unto itself,[3] relevant for a variety of purposes such as search, indexing, or machine translation. It is also a subset of the Pinyin transcription problem.
Phonetic ambiguity. Many characters, including some of the most frequent ones, are phonetically ambiguous: they have two or more alternative readings, only one of which is correct in any given context.
Conventional approaches rely fundamentally on dictionaries, which contain a large part of the vocabulary along with the transcription of each word. Dictionaries are complemented by heuristics and hand-crafted rules to obtain the best word segmentation; to choose the most likely reading of ambiguous characters; to recognize proper names; and to observe the finer points of Pinyin orthography, e.g., regarding measure words and particles.[4][5]
A straightforward machine learning approach would train a model from a few million sentence pairs in characters and in Pinyin. Should there be no such character/Pinyin parallel corpus available, but at least we had large amounts of separate character and Pinyin texts somewhere, then there are still unsupervised or adversarial learning approaches available.[6] In reality, there are no multimillion-sentence Pinyin corpora anywhere in existence. Today’s AI approaches appear to be at a disadvantage for the Pinyin transcription problem.
Experiment design
The tools tested. The two tools I decided to compare are Key5[7] and the embedded transcription feature of Google Translate. Looking for other alternatives, a quick search yields several websites claiming to transcribe or annotate Chinese text. I failed to find even a single one, however, that appears to do more than naïve dictionary-based segmentation. The output of such an approach is too bad even to serve as a baseline for the real tools. If you are aware of other tools worthy of a close look, please let me know.
Key5 is a desktop tool for the PC and Mac that has been developed by S., P. Leimbigler, W. McKee and W. Zhang since 2000. It comes recommended by Victor Mair; in fact, I learned about Key5 from a Language Log post.[8]
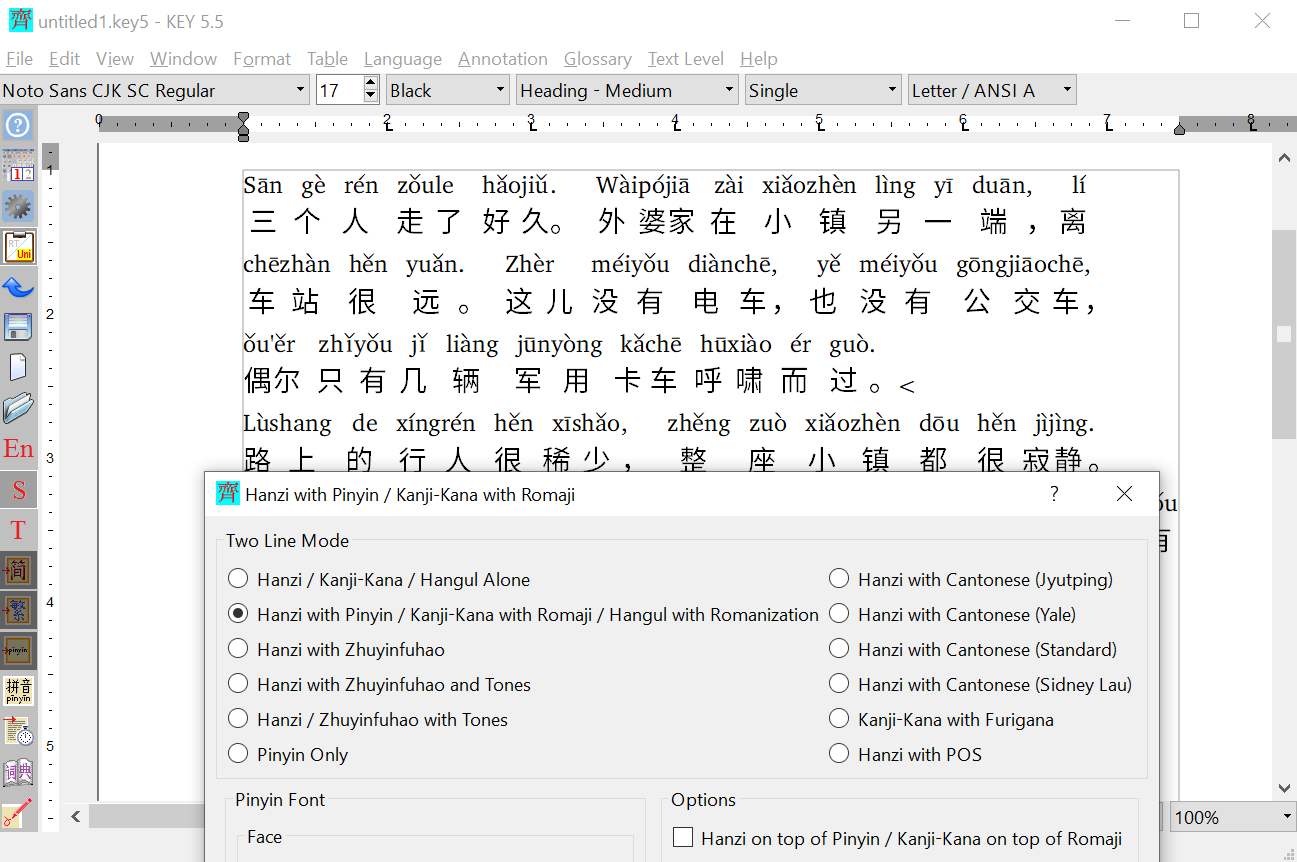
To add Pinyin with proper word-segmentation and capitalization in Key5, I paste character text into a new document; select all text; click Format / Hanzi with Pinyin; and choose the Pinyin option as shown in the screenshot. This is when the magic happens and Key5 annotates the text with word-segmented, phonetically disambiguated Pinyin. The annotated file can then be saved as Unicode UTF-8 text: it will contain two lines per paragraph, one with Pinyin, one with characters.
The other tool is Google Translate’s browser-based interface. If you paste Chinese into the source box, then along with the translation on the right, you also get to read a Pinyin transcription under the source text. From the browser’s Developer Console, this can conveniently be copied, and then pasted into a text file.
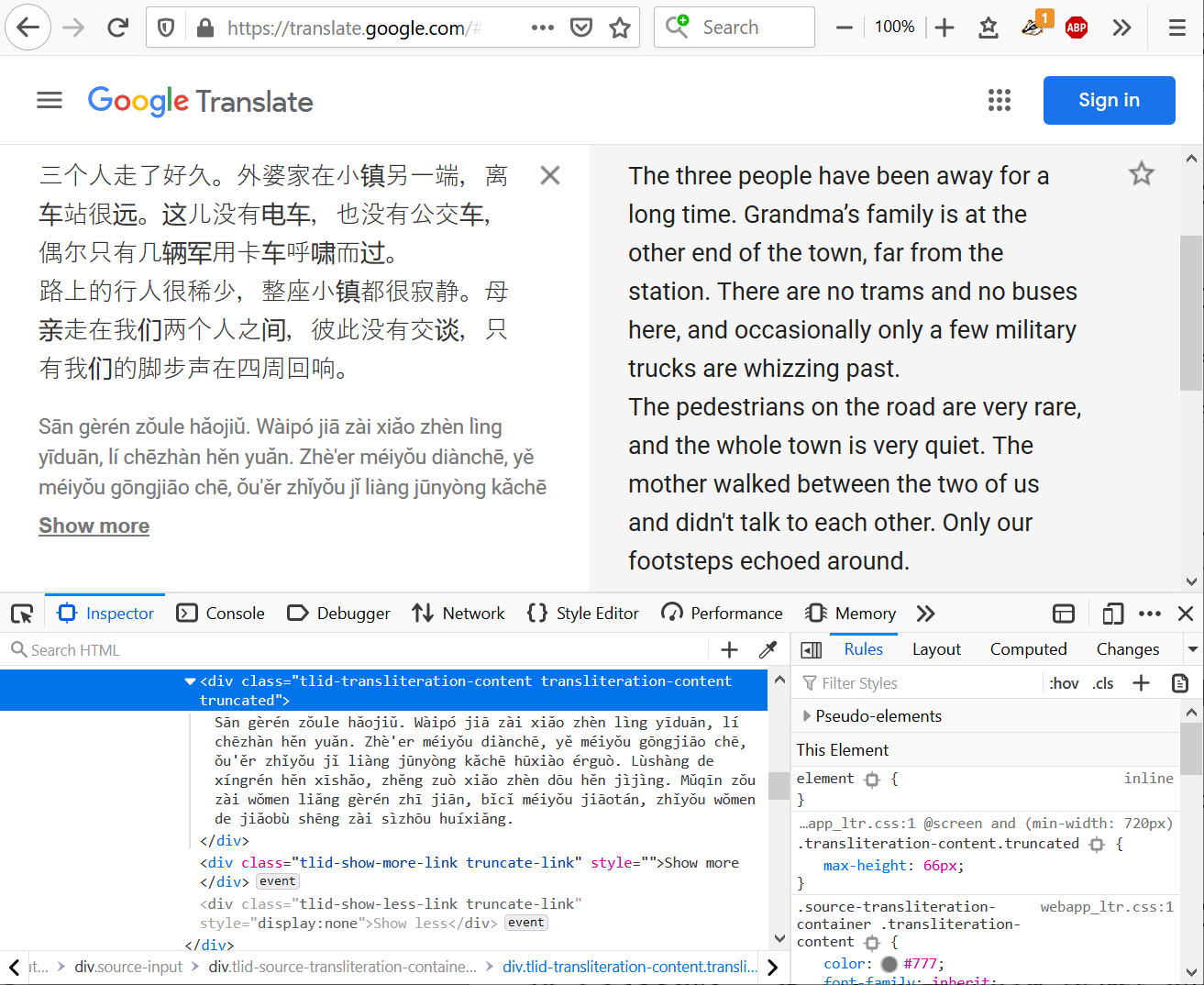
Dataset and annotation. I used two short chapters from a work of fiction for the purpose of this experiment. The chapters are from a published translation of Agota Kristof’s novel Le grand cahier (The Notebook) into Chinese (simplified characters). I produced a Pinyin transcription using both tools as described above, and manually created a “ground truth” version by a close reading of the two automatic transcriptions, paying attention to the correct reading of each character, tones, and proper word segmentation. I do not investigate punctuation and capitalization in this experiment.
You can view the ground truth as a PDF file via this link. I share all data files at the bottom of this post. I’m happy to share the scripts I used to produce them upon request.
Evaluation: the numbers
In order to make the tools’ outputs comparable, I defined various word segmentation and phonetic transcription errors. Each of these errors is defined on a syllable level; a syllable is defined as one non-punctuation Chinese character. (The data has 6 occurrences of erhua 儿 in 2234 characters, which means equating syllables with characters is an acceptable generalization that adds only negligible error.)
Segmentation errors:
-
Incorrectly glued: the tool joined a syllable with the following syllable, but they ought to be written separately.
Example: 一本 → yīběn instead of yī běn -
Incorrectly split: the tool did not join a syllable with the following syllable, but they ought to be written together.
Example: 来自 → lái zì instead of láizì
Phonetic transcription errors:
-
Should be neutral tone: A syllable should have neutral tone, but the tool assigned a full tone to it, while otherwise picking
the correct Pinyin syllable.
Example: 母亲 → mǔqīn instead of mǔqin -
Wrong neutral tone: A syllable should have a full tone, but the tool assigned neutral tone to it, while otherwise picking the
correct Pinyin syllable.
Example: 里 → li instead of lǐ (in a specific context) -
Wrong Pinyin: The tool picked a wrong reading for the character in the specific context where it occurs.
Example: 的 → dì instead of de (in a specific context)
Defining the problems on a syllable level makes it possible to calculate comparable error percentages, even if word segmentation is different across the tools. You can view the entire output of both tools, with problems highlighted inline, via these two links:
Detailed evaluation of Google MT’s Pinyin transcription
Detailed evaluation of Key5’s Pinyin transcription
The table below shows the summary results for Google MT and Key5.
| Metric | Google MT | Key5 |
| Hanzi count | 2234 | 2234 |
| Word count | 1478 | 1478 |
| Incorrectly glued | 24 (1.07%) | 133 (5.95%) |
| Incorrectly split | 105 (4.70%) | 59 (2.64%) |
| Total segmentation errors | 129 (5.77%) | 192 (8.59%) |
| Should be neutral tone | 68 (3.04%) | 10 (0.45%) |
| Wrong neutral tone | 5 (0.22%) | 40 (1.79%) |
| Wrong pinyin | 28 (1.25%) | 13 (0.58%) |
Evaluation: subjective notes
I’ve used both tools extensively to annotate Chinese text for myself. The numbers above, together with the annotated samples, confirm the impressions I have gathered along the way.
Google MT is more inclined to split words that should be written together; Key5, conversely, is a bit over-eager to join what doesn’t belong together. Overall, Key5’s segmentation is a bit more off that Google’s.
Most segmentation errors are fairly innocuous, involving particles glued to the preceding word and the like. Often, as far as I can tell, Pinyin’s orthographic rules are not completely clear either, and for lack of an extensive orthographic dictionary, it’s hard to decide whether a given combination is a compound word that should be written together, or just a random encounter.
Some incorrectly joined syllables, however, are really bizarre, e.g.:
长什么模样我都不知道
zhǎng shénme múyàngwǒ dōu bù zhīdào
Key5’s decision to join múyàng with wǒ is hard to explain with either a heuristic or a wrong dictionary entry. While both tools produce this type of error, overall Key5’s output is less pleasant to read because of them.
A frequent, innocuous phonetic transcription error is using a full tone where neutral tone is warranted, or vice versa. Google appears to err on the side of full tones, while Key5 chooses the neutral tone more often. Neither of these affect very many syllables, though.
A more annoying transcription error is choosing a rare, wrong pronunciation for some of the frequent particles: e.g., 的 (dì instead of de) or 着 (zháo instead of zhe). Google is definitely the worse offender here. Although the percentage of this type or error is quite low in the evaluated sample, these errors are particularly jarring; in my subjective perception, they appear more prevalent than they really are.
Curiously, Google occasionally throws in an incorrect syllable that comes completely out of the blue, a syllable that is not even among the character’s possible readings at all. This includes 道 as dáo, with the second tone, or, even more bizarrely, 啜 as chuài (instead of chuò). It is extremely unlikely that such false readings were introduced into Google MT from any existing dataset like a dictionary or the Unihan database. Where they come from is just as mysterious as the full algorithm behind Google MT’s Pinyin transcriptions.
For my practical purposes, I can obtain the best outcome by combining the two tools: use Key5’s output for pronunciation, but Google’s output for word segmentation. This combined result needs perceivably less human verification and editing.
Data
eval-interlaced.txt
contains the unsegmented Hanzi that was the input of both tools, interlaced with the Pinyin transcription that is the ground truth
for the evaluation.
eval-ground-truth.pdf
is a more human-readable form of this exact file.
eval-GoogleMT.txt and
eval-Key5.txt
are the outputs of the two tools being tested.
References
[1] en.wikipedia.org/wiki/Pinyin
[2] www.pinyin.info/index.html
[3] The best tool out there, as far as I can tell, is ICTLAS. To get a grasp of the problem of Chinese word
segmentation, skim the original paper. It's not exactly new, but apparently some things age really well.
Hua-Ping Zhang, Hong-Kui Yu, De-Yi Xiong, Qun Liu: HHMM-based Chinese Lexical Analyzer ICTCLAS.
Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, Sapporo, Japan, 2003.
[PDF].
[4] Jun Xu, Guohong Fu and Haizhou Li:
Grapheme-to-Phoneme Conversion for Chinese Text-to-Speech.
In: INTERSPEECH 2004 - ICSLP, 8th International Conference on Spoken Language Processing, 2004.
[PDF]
Just the abstract of the paper below gives a great glimpse into the problem of Pinyin transcription.
Several methods were developed to improve grapheme-to-phoneme (G2P) conversion models for Chinese text-to-speech (TTS) systems.
The critical problem of data sparsity was handled by combining approaches. First, a text-selection method was designed to cover as many
G2P text corpus contexts as possible. Then, various data-driven modeling methods were used with comparisons to select the best method for
each polyphonic word. Finally, independent models were used for some neutral tone words in addition to the normal G2P models to achieve more
compact and flexible G2P models. Tests show that these methods reduce the relative errors by 50% for both normal polyphonic words and Chinese
neutral tones.
Lifu Yi, Jian Li, Jie Hao, Ziyu Xiong: Improved grapheme-to-phoneme conversion for mandarin TTS.
In: Tsinghua Science and Technology (Vol. 14, Issue 5, Oct 2009)
ieeexplore.ieee.org/document/6076259
[5] Personal communication from Key5's Will McKee.
[6] A similar approach is used to train machine translation engines for underresourced language pairs. E.g.: Mikel Artetxe, Gorka Labaka, Eneko Agirre, Kyunghyun Cho: Unsupervised Neural Machine Translation. In: ICLR 2018 proceedings. arxiv.org/abs/1710.11041
[7] cjkware.com
[8] Pinyin for phonetic annotation. Victor Mair on Language Log, October 27, 2018.