Regexing the daylights out of an iOS localization package
The is Part 1 of the series Localizing an iOS drawing app with memoQ, one cliffhanger at a time.
UPDATE: Marek Pawelec just messaged me on Twitter to say he already did this part almost three years ago. By all means go and read his post, Localizing iOS .strings files with memoQ. If "Regex Wizard" is a thing, than Marek is that person.
The iOS localization package I received contains a bunch of text files. All of them have a simple enough structure, like so:
/* Distribute Horizontally */ "Distribute Horizontally" = "Distribute Horizontally"; /* Distribute Vertically */ "Distribute Vertically" = "Distribute Vertically"; /* Download Problem */ "Download Problem" = "Download Problem"; /* Downloading “%@” */ "Downloading “%@”" = "Downloading “%@”";
The first line is always a comment. Left of the equation sign is what you could consider, with some generosity, a context ID; to the right is the text to translate, in quotation marks. memoQ has no built-in filter for this format, but it’s peanuts for the Regex Text filter. On to a fresh English-Hungarian project; click Import With Options; then, in the dialog for Document import options, click Change filter and configuration for all. Now we’re talking! This is the window to configure the Regex Text filter.
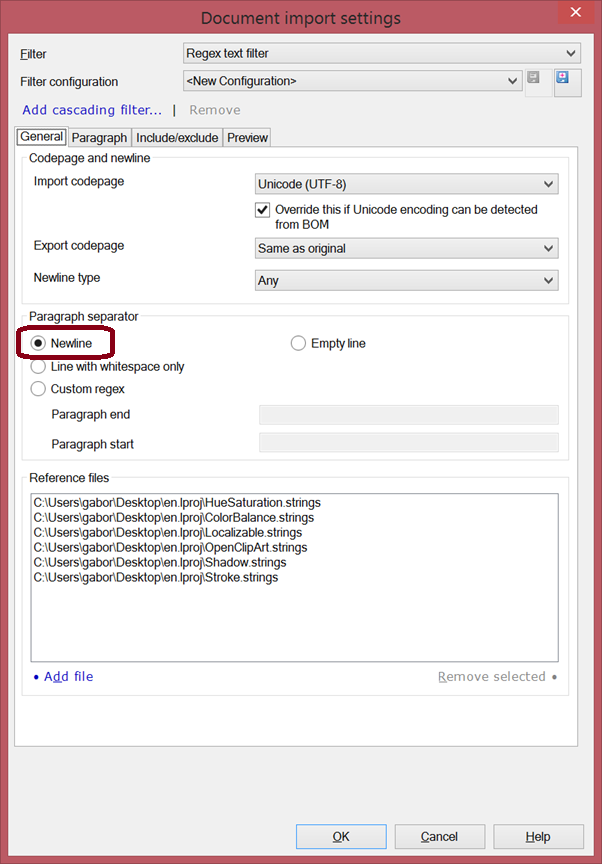
The first thing to change is the paragraph separator. In our files each section we care about is made up of two lines, and the sections are separated by empty lines, so the second option, Line with whitespace only will work fabulously. On to the Paragraph tab, where we’ll define how to parse each section.
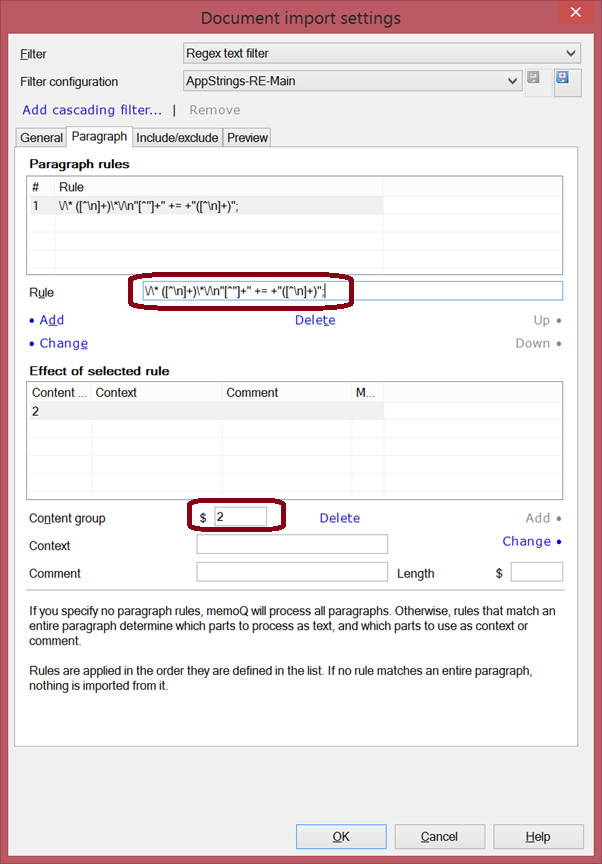
A single regex will do the trick.
\/\* ([^\n]+)\*\/\n"[^"]+" += +"([^\n]+)";
In quasi-human language, this will match:
| \/\* | /* , followed by |
| ([^\n]+) | a bunch of characters that are not line breaks, followed by |
| \*\/\n | */ and a line break, followed by |
| "[^"]+" += + | a quotation mark, a bunch of non-quotation marks, another quotation mark, one or more spaces, the equal sign, and one or more spaces, followed by |
| "([^\n]+)"; | a quotation mark, a bunch of characters that are not line breaks, a quotation mark, and a semicolon. |
That’s precisely the pattern we see in the text files. The two parts of the regex that are in parentheses define groups: text that memoQ will capture during the import. The first group is superfluous: I was considering to use it as a context ID, but eventually decided not to. The second group is the text to be translated. That’s the only thing we need in the rule’s details under Effect of selected rule: group 2 is our Content group.
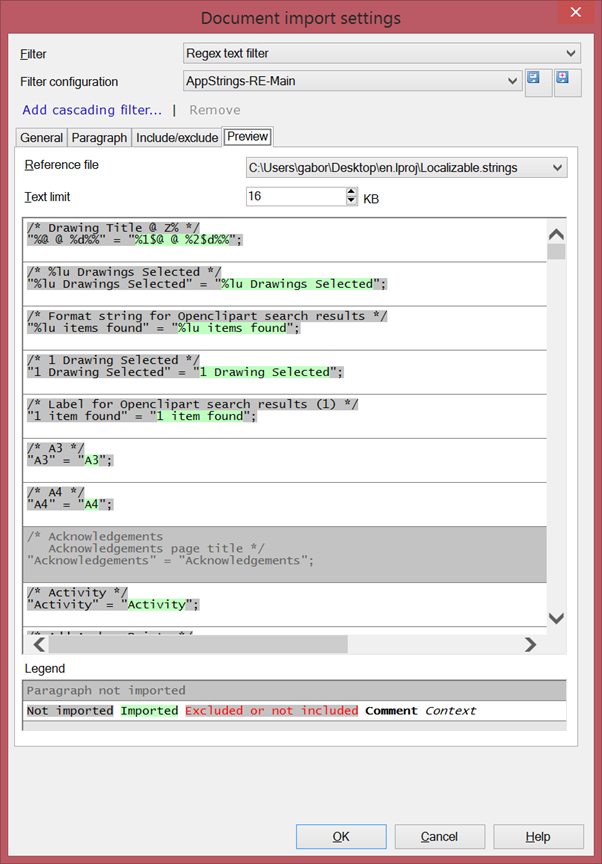
Kid youself not: in real life, regex is never that easy. It’s a continuous trial-and-error until you finally get it right. To know just how far you are, you can always switch to the Preview tab and see, at a glance, how your current regex slices up the input. This is what you’ll get as a preview for translation, too.
With all the effort you put into that regex, you want to make sure you can use it again in the future, so quickly save your work as a new filter configuration. The atavistic floppy disk icon at the top right does just that.
Are we ready to start translating yet? Or is there more localization engineering needed to groom these iOS files? Check the next instalment to find out!
Part 2: Workplace safety: get placeholders out of the way with the regex tagger
