Mine 200 thousand words of translated content through memoQ’s hands-off aligner and translating concordance
The is Part 5 of the series Localizing an iOS drawing app with memoQ, one cliffhanger at a time.
Endgame! I’m almost there! I have two XLIFF files converted from a 500-page user guide in English and its Hungarian translation. Whatever questions I have about vector graphical terms of art, the answers are almost certainly in there. But how can I get memoQ to cooperate in my interrogation?
What I need is an alignment of the two texts. That’s a very powerful function of advanced CAT tools that looks at a source document and its translated counterpart, splits the text into sentences, and matches up each of those sentences in both languages. That is a non-trivial thing to do because many sentences are not translated one-to-one. Also, if you think of a user guide, it will have an index at the end that is ordered alphabetically – in both languages. Pretty much every real-life document pair will have parts that are, on some level, translations of each other, but with the sentences/items shuffled around and rearranged at will.
Let’s start the with English file. I’ll need a memoQ project whose languages are English to Hungarian, because that’s the combination I specified when creating the XLIFF through TransPDF. Once you import the XLIFF and open it in memoQ’s editor, you can see it looks something like this inside:
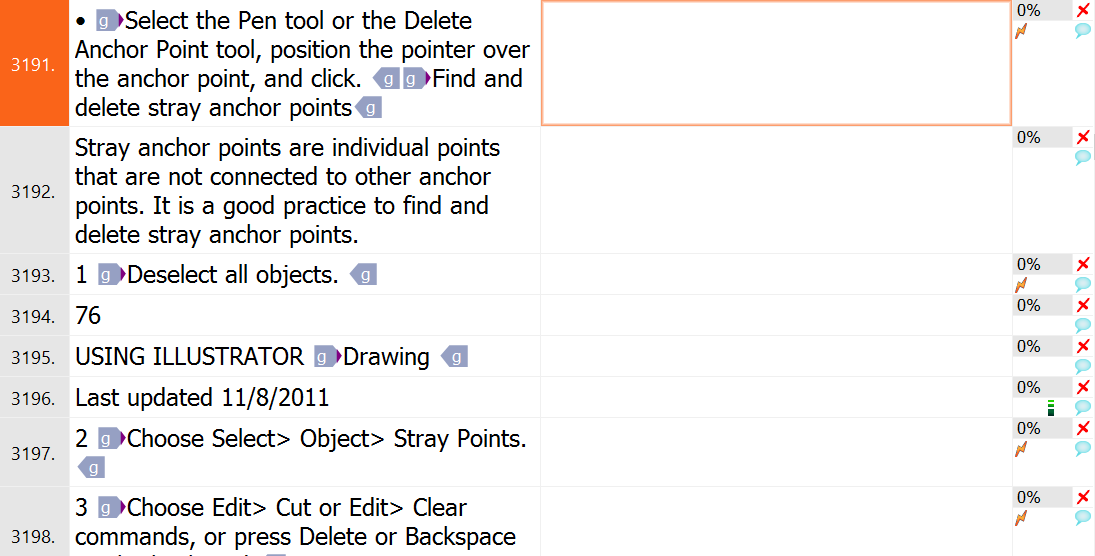
I could throw the English and the Hungarian documents straight at the aligner and the result might not even be horribly bad, but a few small changes at this stage will pay off massively. You can see that the XLIFF includes page numbers and chapter titles, plus a “Last updated” notice, from each page’s header and footer. The problem is, these break the English and the Hungarian text flow at different places, so they’ll make it more difficult for the aligner to match up the segments. Let’s indulge in a bit of localization engineering and remove them!
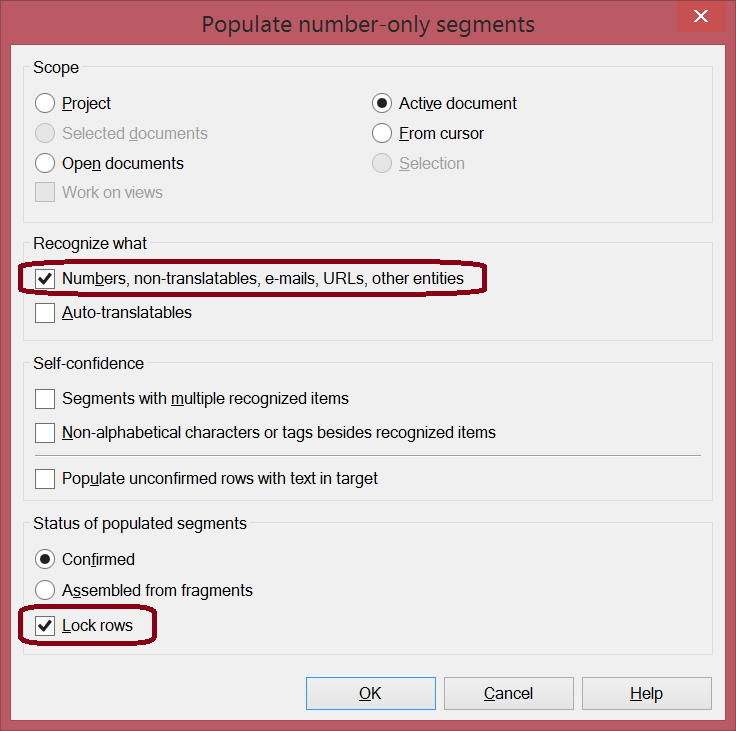
Get page numbers out of the way. I’ll use Populate number-only segments from the Preparation ribbon tab for this. This is a function that can deal with a bunch of other things too, but here I really only need those numbers out of the way. Hence, all check boxes cleared except the first one under Recognize what. Importantly, notice that I did check Lock rows at the very bottom. I’m working to build up a situation where all the segments I don’t need are locked.
Get rid of recurring text in headers and footers. For the rest, let’s filter for a characteristic part of the recurring header and footer texts. First, select “USING ILLUSTRATOR” and hit Ctrl+Shift+F to show only segments that have this text. That’s mostly only the headers, but if you want to be meticulous, also sort by segment length, and scroll down to where the genuine sentences start.
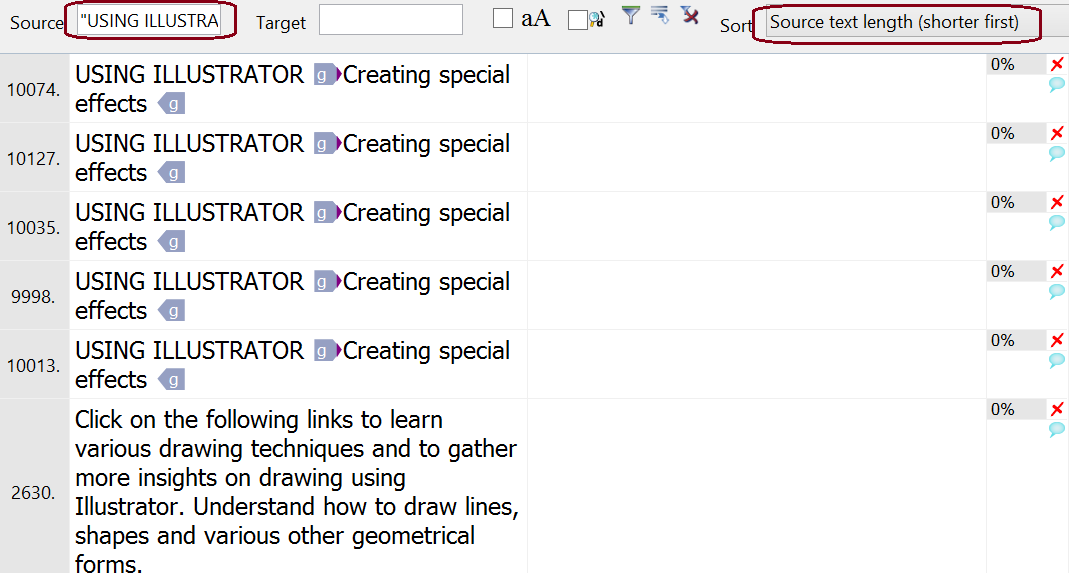
Now select all the segments you want to get rid of. Click on the row number 10013 to select that row; scroll to the very top; then Shift+click on the row number there. That selects everything in between. Press Ctrl+Shift+L to lock these segments. Repeat the same for “Last updated 11/8/2011”.
The inversion move. Great, I have locked all the segments that I want to leave out, but some of them (the numbers) have text in the target. What I want is the source copied to the target everywhere, except in the segments I want to exclude. This step gets a bit quirky, but all the more exciting.
- Start with the document unfiltered
- Press Ctrl+Shift+A to select every segment. Press Ctrl+Shift+S to copy source to target. This will populate target segments with the text from the source, but it will leave the locked segments alone.
- Click on the filter icon above the grid:
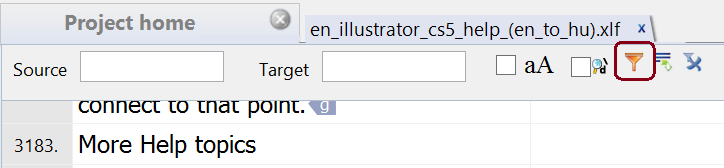
- Select the option to include only locked rows:
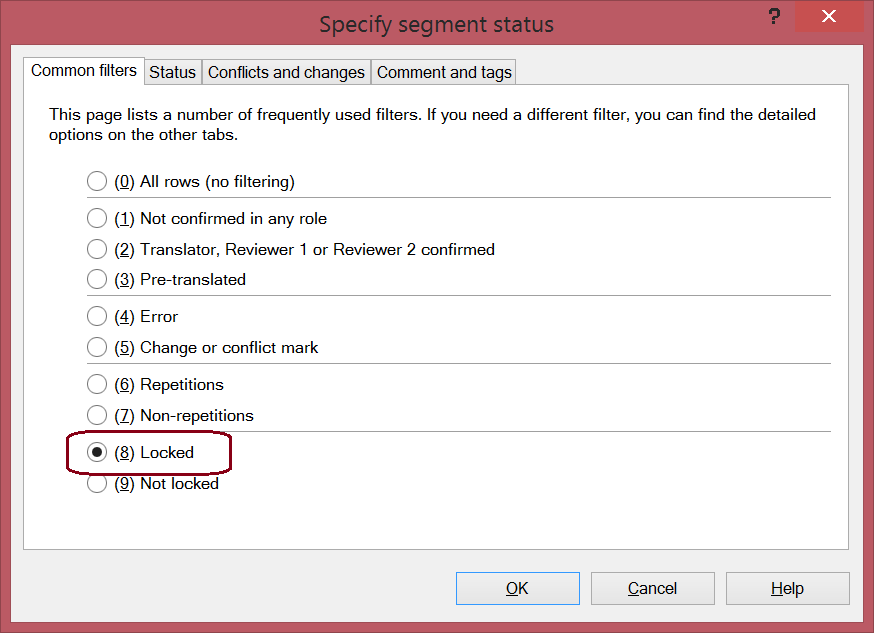
- Now your grid shows only the rows you’ve locked. Press Ctrl+Shift+A to select them all, and Ctrl+Shift+L to unlock them. From the right-click menu, click Clear Translations to remove the numbers that we populated in the target segments previously. Press Ctrl+Shift+L to lock again.
- At this stage, your document looks like this:
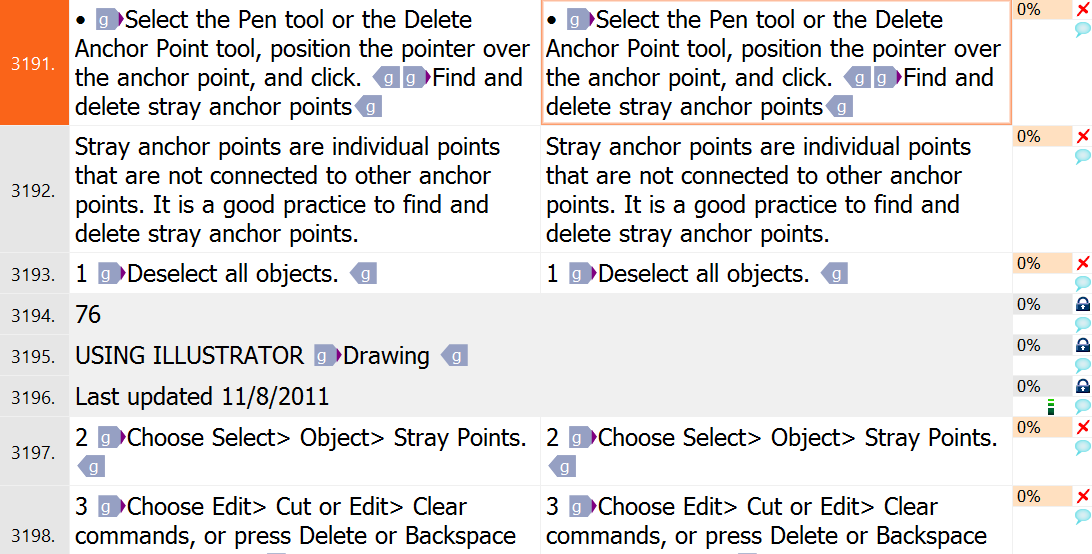
Get the clean text. I’ll use a little-known but extremely cool feature of memoQ for this. While the document is still open, switch to the Documents ribbon tab, and click Export > Export Active Document As Plain Text.
Tada! You have the content from the English PDF as a plain text file, with all the headers, footers and page numbers removed! Repeat for the target-language file in a memoQ project with the opposite language combination.
Bear with me; we’re almost there. All that remains now is to throw these two text files at memoQ’s aligner. Let's return to the project that I created for actually translating Inkpad’s files. Under Project home:
- Go to Translation memories and create a TM that will receive the aligned segments
- Go to LiveDocs and create a new corpus
- Use Add Alignment Pairs from the LiveDocs ribbon tab to import the two text files for alignment
- Without even opening the alignment to fix anything, right-click it and click Export To TM. Select the TM you created and make sure to uncheck Only confirmed (blue) links. None of the alignments are manually verified here!
And that’s it. In four short steps I’ve made memoQ automatically align the two files with about 14 thousand segments each, and stored the result in a TM. It will be full of errors, but it doesn’t matter. I don’t want to reuse the actual translations; I just want to mine this content for the expressions I don’t know. As a human I’ll be able to cut through the extra noise that’s in there.
What does that mean in practice, precisely? Let’s say I’m not certain what a swatch is called in Hungarian vector graphics software. (Honestly, dear reader: do you know what it means in English, even?) I can do a quick concordance search:
![]()
This gives me all the source segments where swatch occurred in the English manual, along with the translations that the aligner put next to them. These translations will occasionally be a few segments off, but overwhelmingly, they will be the right ones. And because I checked Guess translations and raised the limit on retrieved results to the maximum, memoQ will do an awesome job also at finding out, statistically, just what the translation of swatch most likely is. Those are the green highlights you see in the Hungarian.
With this, I have no excuse left but to translate Inkpad. That means I’ll be off for a couple of hours now. Check back in a bit, or better still: go to the App Store, download Inkpad, and enjoy the translations if your device’s language is set to Hungarian.
