What’s cooking in the Hungarian NLP scene? MSZNY 2018 conference report.
I got into @kisb971’s car last Thursday and we headed down to Szeged to attend the 14th conference on Hungarian computational linguistics.[1] These were two days packed with inspiring presentations and chats, and I thought I’d write it all up while the impressions are still fresh. What you’re reading below is not a complete or balanced account; it is biased towards what resonated most with my personal interests.
Sin tax and some antics; plus, speech
When I write packed, I really mean packed. The conference’s single track featured 24 talks, 10 posters and roughly 6 demos. The talks were grouped into blocks about Syntax; Semantics and Information Retrieval; Corpora and Basic Infrastructure; Speech; and Multilingual Approaches. In my mind I see patterns that cut right through these topics, so I’ll follow a somewhat different tack here.
I’ll be listing the titles in each section; you can find the referenced papers in the MSZNY 2018 conference volume.[2] The Hungarian titles’ translations are my own.
Before I delve into the details, two general impressions. First, the presentations were invariably awesome. No death by Powerpoint, no awkward speakers. Seeing so much great delivery in such a short time, I can’t help but remember my own clumsy self years back, before I was hardened by so many product demos and webinars.
Then, I am impressed by how natural and spontaneous all the talks were. I haven’t been to an academic conference in over ten years; I’ve grown accustomed to the antics of trade shows and industry events. Listening to these talks, I felt they were no different from an informal chat I’d have if I met the presenter on a random train ride or flight, and we just shared news about what we’ve both been up to in our research since we last met. I could spend not two days but weeks with this crowd, and never get bored of it.

The sparse, the dense and the neural
Manual evaluation of Hungarian word embedding models
Magyar szóbeágyazási modellek kézi kiértékelése
Attila Novák, Borbála NovákTowards cross-lingual utilization of sparse word representations
Gábor BerendCombining machine translation systems through quality evaluation
Gépi fordítórendszerek kombinálása minőségbecslés segítségével
László János Laki, Győző Zijian YangHyphenation using deep neural networks
Gergely Dániel Németh, Judit ÁcsAn experimental comparison of the deep neural state transition algorithms of speech recognition systems
Beszédfelismerők mély neuronhálós állapotkapcsolási algoritmusainak kísérleti összehasonlítása
László Tóth, Tamás Grósz, Gábor GosztolyaRestoring punctuation in TV subtitles with recurrent neural networks
Televíziós feliratok írásjeleinek visszaállítása rekurrens neurális hálózatokkal
Máté Ákos Tündik, Balázs Tarján, György SzaszákAttempts to estimate base frequency with deep neural networks in ultrasound silent speech interfaces
Kísérletek az alapfrekvencia becslésére mély neuronhálós, ultrahang-alapú némabeszéd-interfészekben
Tamás Grósz, László Tóth, Gábor Gosztolya, Tamás Gábor Csapó, Alexandra Markó
For my technology-focused mind, the papers that involve word embeddings and neural networks are what stand out most. Clearly these two approaches, which usually go hand in hand, have washed over the NLP scene in the past few years like a tsunami.
The word embedding tide reached Hungary with a negligible delay. By this year, work such as Novák & Novák about manual model evaluation shows that the method has become, erhm, firmly embedded in our toolset. My only wish would be for a gold standard dataset instead of the one-off approach that cannot be automatically reused to evaluate new models.
Berend’s work is an exciting approach to create sparse (or even binary) models from dense ones in a way that preserves the desirable algebraic properties through a linear transformation into a different language’s vector space.
Somewhat surprisingly, there was no report of neural MT this year. Then again, it’s hard to surpass last year’s result by Tihanyi & Oravecz. Laki & Yang showed how to train a quality evaluator to pick the best translation from multiple MT models, leading to a significant improvement in final quality. The approach is not unlike a committee of experts, boosted by hiring a well-trained judge.
The results of Németh & Ács are refreshing because the authors applied neural networks to a task that is not MT: namely, to learn the behavior of an existing, rules-based hyphenator. I’m expecting many similar non-MT applications in the future, hoping in particular for a combined morphology/tagger/lemmatizer that would generalize well to new words and forms.
The section where neural rules supreme this year is clearly speech technology. Half of all the speech papers build heavily on neural networks, and show impressive improvements over pre-neural approaches.
Digital and human
Inducing Semantic Micro-Clusters from Deep Multi-View Representations of Novels[3]
Minden könyv másképp hasonló – Tartalomalapú, interpretálható szemantikus hasonlóság irodalmi szövegekben
György Szarvas
-- keynote --Narrative analysis of a Russian corpus (NaRu) with custom-developed sentiment and emotion dictionaries
Egy orosz nyelvű korpusz (NarRu) narratívaelemzése saját fejlesztésű szentiment- és emóciószótárakkal
Zsófi Nyíri, Martina Katalin Szabó, Virág IlyésFake or not? Automatic identification of fake news articles in Hungarian.
Kacsa vagy nem kacsa? Magyar nyelvű álhírek automatikus azonosítása
Veronika VinczeProcessing, analyzing and visualizing the Rákosi era’s party records with text-based network analysis
A Rákosi-éra pártjegyzőkönyveinek feldolgozása, elemzése és vizualizációja szövegalapú kapcsolatháló-elemzési módszerekkel
Attila Gulyás, Martina Katalin Szabó, István Boros Jr, Gergő Havadi“And they’ve been living happily ever since, singing cheerful songs abut Lenin and Stalin.” An attempt at the genre classification of Soviet propaganda tales.
„S azóta jól élnek és vidám dalokat énekelnek Leninről és Sztálinról.” Szovjet propagandamesék műfaji azonosításának kísérlete
Csilla Horváth
-- poster --
This group of papers also comes from different blocks of the conference; what connects them for me is their broader reach towards humanities and social sciences.
Szarvas’s keynote stands out to me the most. It mobilizes impressive research building on top of recent precursors and creates a more refined representation of plots in prose fiction. The outcome of the unsupervised method forms the basis of a thematic recommendation engine that is directly usable in Amazon’s e-commerce business. Also, this mind-blowing chart from the presentation is possibly what made the deepest impression on me in the entire two days. Does anyone have an explanation for this dynamic?
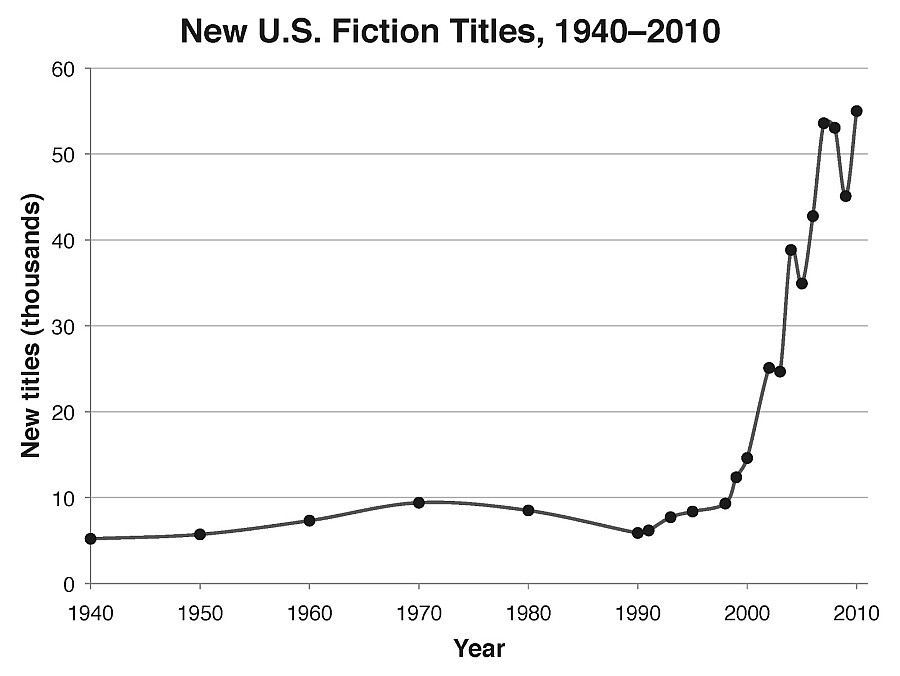
Similar in theme is Nyíri, Szabó & Ilyés’s paper about narrative analysis of Russian novels through emotion and sentiment. I can’t stop thinking about the potential of such approaches for data visualization and literary scholarship. Or even history, as the work about the analysis of Soviet propaganda tales or Rákosi-era party records shows.
A note of incredulity about the latter: this research involves scanning and manually fixing hundreds of pages of low-quality scanned documents. For some unfathomable reason, the Historical Archive seems to believe the privacy of a few potentially surviving Stalinist apparatchiks outweighs the benefits of open discourse about this 70-year-old chapter of history. In other words, after the immense effort put into digitizing this corpus, chances are slim it will ever show up as an accessible source for future research.
Vincze’s work builds a classifier to distinguish fake news articles from real ones. However, “fake news” in this context really means satire. The tool probably picks up stylistic markers more than anything else, and it’s not meant to spot fake news in the Russia Today or the Macedonian teenager[4] sense. Then again, the Silicon Valley giants are not having much luck creating such a tool either, so, hey.
Foundations
Mazsola, for everyone
Mazsola – mindenkinek
Bálint SassAll crawls lead to the same corpus: corpus building from CommonCrawl’s .hu domains
Közös crawlnak is egy korpusz a vége -- Korpuszépítés a CommonCrawl .hu domainjából
Balázs IndigNormo: An automatic normalizatiob tool for Middle Hungarian texts
Normo: Egy automatikus normalizáló eszköz középmagyar szövegekhez
Noémi Vadász, Eszter SimonLemma or not?
Lemmi vagy nem lemmi
Attila Novák, Borbála NovákAutomatic creation of lexical resources for minority Finno-Ugric languages
Lexikai erőforrások automatikus előállítása kisebbségi finnugor nyelvekre
Eszter Simon, Iván Mittelholcz, Zsanett FerencziQuality assurance efforts in the transcription and annotation of the HuTongue spontaneous speech corpus
A HuTongue spontán beszélt nyelvi korpusz leiratozásának és annotálásának minőségbiztosítási munkálatai
Attila Gulyás, Júlia Galántai, Martina Katalin Szabó, Zea Szebeni
-- poster --
While it’s easy and natural to be impressed by the quantum leap of machine learning driven by high-octane GPUs, it’s great to see that a lot of foundational work also continues. This is all the more important because even the shiniest methods will produce underwhelming results if we don’t have the right amount of data to feed them, and the right quality data.
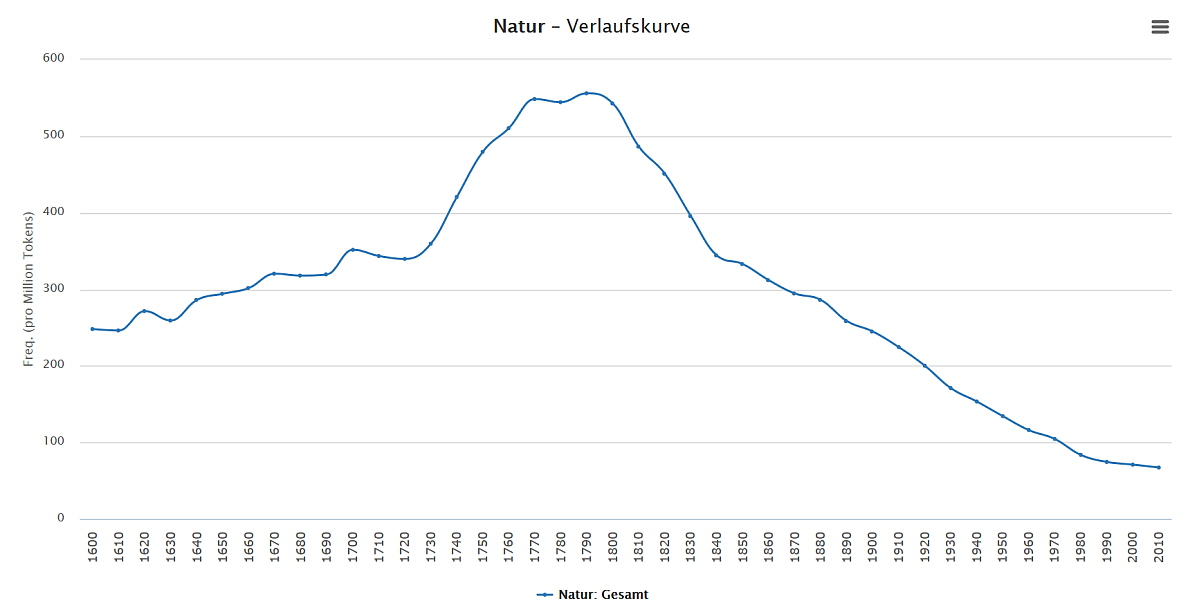
Corpus-building from CommonCrawl, as presented by Indig, is the macro side of things. But we also have Normo for normalizing Middle Hungarian texts, bringing us closer to a complete diachronic view of Hungarian. I can hardly wait for the day when we have a dictionary with historical word frequency curves, such as this one for German:
Going even more micro, Simon, Mittelholcz & Ferenczi are working to record and share the vocabulary of Finno-Ugric languages, often with a vanishingly small population of speakers. I can’t even begin to express the respect I have for this effort, which is a huge contribution to preserving diversity and human cultural heritage in a time of accelerating language extinction.
And then we have tools. Novák & Novák will never stop improving Hungarian morphology, and we’re all the better off for it. Sass made public the code of Mazsola, a powerful query tool behind the online version of the Hungarian National Corpus.[5] If you have a large corpus lying around somewhere and you don’t have a way to explore verb arguments, you are now in luck.
Theory
Constructing and using a standardized Hungarian verbal argument dictionary
Egy egységesített magyar igei vonzatkerettár építése és felhasználása
Noémi Vadász, Ágnes Kalivoda, Balázs IndigNull or nothing? Case disambiguation within the window.
Nulla vagy semmi? Esetegyértelműsítés az ablakban
Noémi Ligeti-Nagy, Noémi Vadász, Andrea Dömötör, Balázs IndigPostpositions first! A corpus-driven analysis of postposition-like items.
Névutók, előre! Korpuszvezérelt elemzés a névutószerű elemekről
Noémi Ligeti-Nagy
We Hungarians hold theory in high esteem, so it’s no surprise that the talks about syntax had place of honor as the first block of the program. And that’s perfectly right too. I like this reminder that real insight about language still comes from human linguists, and not from the brute-force-on-steroids approaches of black-box machine learning.
Ligeti-Nagy explores the continuum stretching from case markers over postpositions to adverbs with arguments, situating the problem in the context of existing literature. But while previous scholarship primarily relied on speakers’ intuition to decide tests, the approach presented here analyzes and mines a corpus to decide on the basis of concrete attestations. The empirical scientist moans with delight.
Confession time: yours truly missed the train to become a real linguist many years ago. As much as he moaned with empirical postpositional delight, he was at a loss when in a different talk, Ligeti-Nagy was mining the same corpus for a distinction between nothings, null-elements, and null-elements denoted by a different Greek letter. Witty remarks about Chomsky getting intoxicated on pálinka are now officially denied, and I publicly admit to being an unwashed layperson.
The odd ones out
The World is Built with our Words to Each Other -- Basic and Fine-Tuned Intensional Profiles in Hungarian
Anna Szeteli, Gábor Alberti, Judit Kleiber, Mónika DólaEtudes in Chinese-Hungarian Corpus-Based Lexical Acquisition
Gábor Ugray
I left two talks that I cannot shoehorn into any comfortable box for the end. The first is the mesmerizing research about intensional profiles in Hungarian. The import of this research is best conveyed in the authors’ own words: […] we present how speakers with their psychological egos can be separated from linguistically conventionalized addresser roles and how many pragmasemantic phenomena can be captured through pattern matching between addressers’ conventional profiles and the corresponding speakers’ information states, including a few elements of politeness. In short, the program is ultimately designed to simulate human intelligence through modeling human communication and language-based cognition in order to improve our theoretical background on the basis of the functioning of the program.
The second one is my own paper. I explain how I weaponized an eclectic mix of NLP tools, mining a corpus of movie subtitles in order to acquire new vocabulary for my pet project, the CHDICT Chinese-Hungarian dictionary.
Academia and business
Most of the MSZNY 2018 participants came from academia, but there was a noticeable cohort of folks from business too. The keynote speaker is now with Amazon, though he is in some ways family, having previously been a research associate at the Hungarian Academy of Sciences and the University of Szeged. Precognox presented in collaboration with academia, and we also spotted Spicy Analytics, SpeechTex, MorphoLogic, and Black Swan Hungary. Balázs and I, of course, proudly sported our metaphorical Kilgray hats.
A thank you note
A huge thank you is due to the organizers for a flawless and very rewarding event: Judit Ács, Attila Novák, Eszter Simon, Dávid Sztahó, and Veronika Vincze.
References
[1] rgai.inf.u-szeged.hu/index.php?lang=hu&page=mszny2018program
[2] rgai.inf.u-szeged.hu/project/mszny2018/files/teljesB5.pdf
[3] Lea Frermann, György Szarvas: Inducing Semantic Micro-Clusters from Deep Multi-View Representations of Novels. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
aclanthology.info/papers/D17-1200/d17-1200
[4] Inside The Macedonian Fake-News Complex. By Samanth Subramanian. Wired, February 15, 2017.
www.wired.com/2017/02/veles-macedonia-fake-news/